Escalando uma aplicação com Nginx e Docker Container
Introdução
Desta vez, quero falar um pouco sobre escalabilidade (Scaling) com 4 instâncias de uma aplicação ASP.NET MVC. Para isso vou falar sobre Load Balancing, Scaling e estratégias existentes. Para demonstrar a prática utilizarei Nginx, Docker e uma aplicação API REST. Não importa a tecnologia utilizada, esse conhecimento é agnóstico a frameworks. Foi escolhido ASP.NET porque é o framework que estou aprendendo atualmente e estou construindo um projeto para dominar a tecnologia.
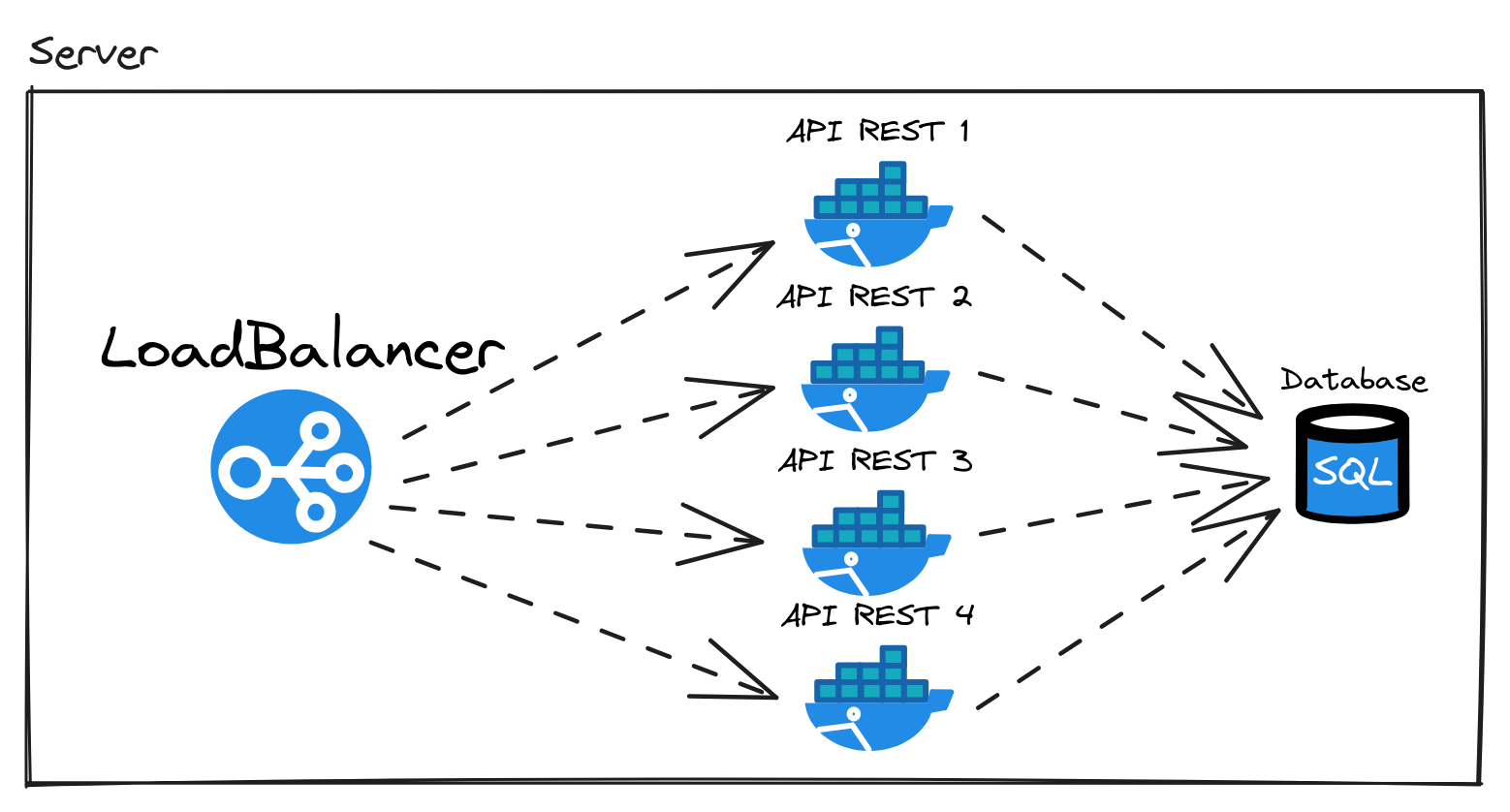
O que é Scaling (Escalabilidade)?
Como dito no livro Designing Data-Intensive Applications por Martin Kleppmann:
Scalability is the term we use to describe a system’s ability to cope with increased load
Então quando a carga aumenta, nós precisamos adaptar a nossa aplicação para conseguir processar a carga com a aplicação funcionando devidamente. A carga aqui é usuários acessando nossa API REST, mas não se limita a isso, em outros casos pode ser writes no banco de dados ou hit rate no cache. No caso da API REST é considerado requests per second. No meu caso hipotético, eu estou criando 4 instâncias de uma API REST pois uma só não é capaz de lidar com a quantidade de requisições.
Não vou me aprofundar muito sobre teorias de escalabilidade mas é o que pretendo estudar mais sobre logo. Para adaptar nossa aplicação, criarei uma instância exata para dividir as requisições entre essas 4 aplicações. Mas como as requisições serão divididas entre essas 4 cópias da aplicação API REST? Load Balancer é a solução para esse problema.
No mundo real cada container desse seria um virtual server da AWS ou Google Cloud, mas como isso é prática de Load Balancer, um único servidor (meu computador) é suficiente para demonstrar. Por que? Quero demonstrar como um Load Balancer funciona e seus benefícios, e não como serviços podem ser divididos entre diferentes servidores.
Load Balancer
Load Balancer é um server que pode distribuir os requests entre servidores. Isso é feito utilizando um algoritmo que é escolhido ao configurar, e dessa forma a carga (Load) é balanceado (Balanced)
Existem alguns métodos de balanceamento de carga, algoritmos que decidem qual servidor escolher. Temos o algoritmo Round Robin, utilizado também por Schedulers, em que a carga é distribuída seguindo a ordem dos servidores em um ciclo.
Um outro método é Least Connections. O load balancer vai escolher o servidor com a menor quantidade de conexões abertas, no caso o com menos carga no momento. Também há o método Generic Hash em que é provido uma hash key para decidir qual servidor irá processar a requisição.
Como soluções de Load Balancer, existem duas escolhas populares: Nginx e HAProxy. Para esse exemplo utilizarei Nginx.
Configuração Nginx como Load Balancer
O método de Round Robin com o Nginx pode ser feito assim. No Nginx, Round Robin é o padrão. No código de configuração abaixo do Nginx, eu estou definindo o grupo de servers em que o método Round Robin vai definir qual deles vai processar a requisição HTTP.
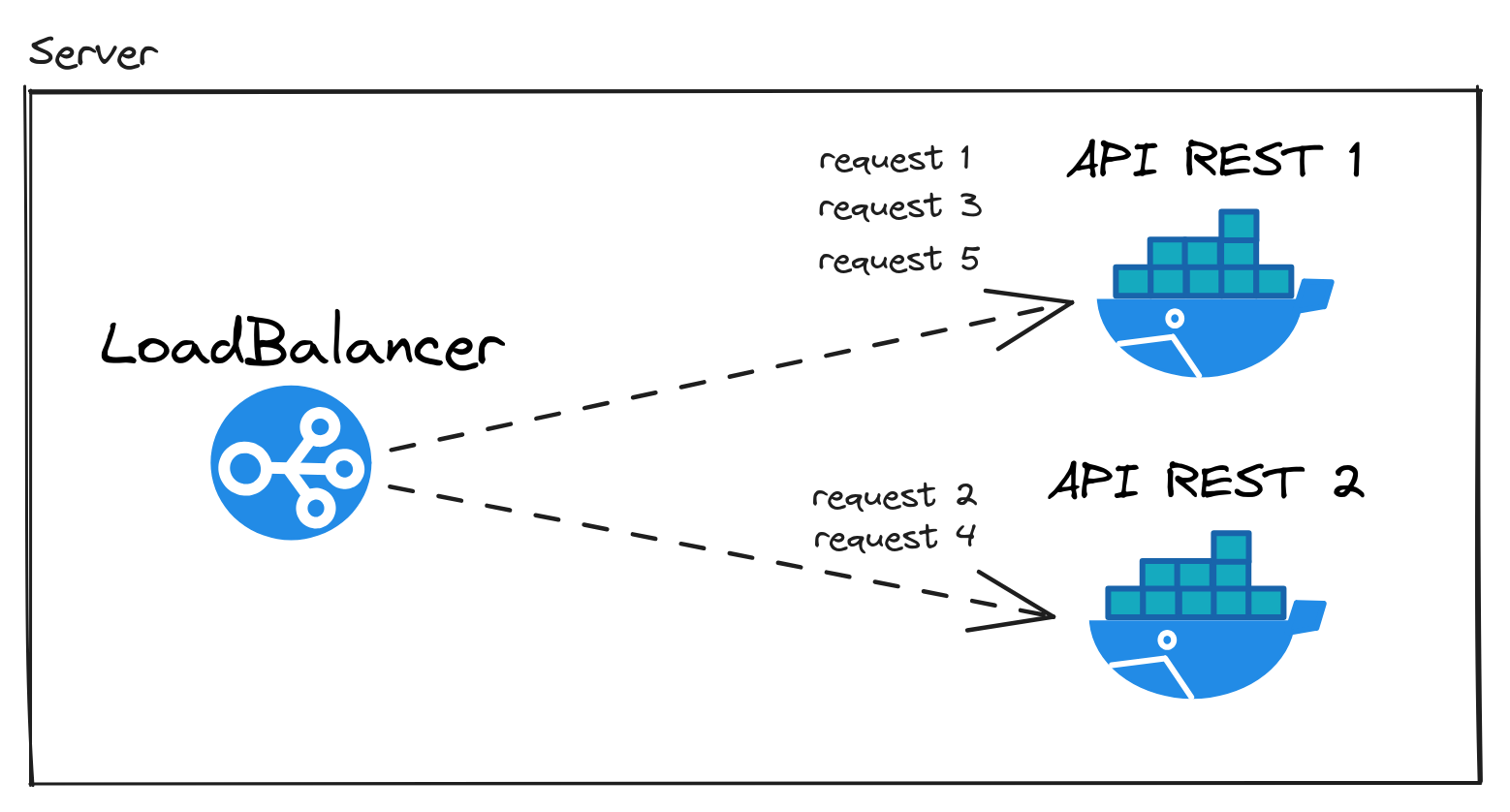
Estou utilizando api-rest-n pois esse é nome do serviço no arquivo docker-compose.yml.
events {
worker_connections 1024;
}
http {
upstream api {
server api-rest-1;
server api-rest-2;
server api-rest-3;
server api-rest-4;
}
server {
listen 80;
location / {
proxy_pass http://api;
}
}
}Para utilizar Least Connections basta inserir a seguinte linha em upstream.
events {
worker_connections 1024;
}
http {
upstream api {
least_conn;
server api-rest-1;
server api-rest-2;
server api-rest-3;
server api-rest-4;
}
server {
listen 80;
location / {
proxy_pass http://api;
}
}
}Cheque a documentação para ver como pode ser feito com os outros métodos.
Escalando nossa aplicação com Docker compose
Como estou utilizando 4 instâncias, ou réplicas, da API REST, serão 4 Docker containers rodando. O docker-compose.yml está configurado assim:
version: '3.7'
services:
load-balancer:
image: nginx:latest
volumes:
- ./nginx.conf:/etc/nginx/nginx.conf:ro
depends_on:
- api-rest-1
- api-rest-2
- api-rest-3
- api-rest-4
ports:
- "80:80"
api-rest-1:
build: .
environment:
DB_HOST: ${DB_HOST}
DB_PORT: ${DB_PORT}
DB_NAME: ${DB_NAME}
DB_USER: ${DB_USER}
DB_PASSWORD: ${DB_PASSWORD}
CORECLR_PROFILER: ${CORECLR_PROFILER}
NEW_RELIC_LICENSE_KEY: ${NEW_RELIC_LICENSE_KEY}
ports:
- 8000-8003:80
restart: always
api-rest-2:
extends: api-rest-1
api-rest-3:
extends: api-rest-1
api-rest-4:
extends: api-rest-1
database:
container_name: ordering-api-database
image: mcr.microsoft.com/mssql/server:2019-latest
environment:
SA_PASSWORD: ${DB_PASSWORD}
ACCEPT_EULA: "Y"
MSSQL_PID: "Developer"
ports:
- 1433:1433
restart: always- Utilizo o extends para utilizar a mesma configuração do serviço api-rest-1 para todas as outras instâncias.
- Defino ports em api-rest-1 como sendo de 8000-8003 para que todas as instâncias da API REST vá da porta 8000 até 8003. Isso é possível graças ao extends.
Resultados
Vamos ver o primeiro resultado para a rota /api que retorna o host name do container em JSON.
namespace OrderingApi.Controllers;
using Microsoft.AspNetCore.Mvc;
[ApiController]
[Route("/api")]
public class ApiInfoController : ControllerBase
{
[HttpGet]
public ActionResult<HttpResponse> GetInstanceInfo()
{
var hostname = System.Environment.MachineName;
return Ok(new { hostname = hostname });
}
}Utilizando a ferramenta wrk para load testing para verificar se os requests per second aumentava com o aumento de instâncias da API REST. Utilizei o seguinte comando:
seq 1 5 | xargs -n1 wrk -t1 -c100 -d30s http://localhost/api >> benchmarks/api-1-replica-100-conn-1-th.logCom esse comando iria rodar o wrk na rota /api 5 vezes com 100 conexões ativas utilizando 1 CPU thread durante 30 segundos. E a cada resultado iria dar append no arquivo de log. Fiz assim para todos os casos mudando somente o número de conexões ativas e os servidores a serem balanceados no arquivo nginx.conf.
CASE 1: Leitura de RAW JSON na /api
Os resultados foram os seguintes:
Running 30s test @ http://localhost/api
1 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 14.14ms 3.33ms 93.40ms 81.16%
Req/Sec 7.12k 453.94 8.04k 77.33%
212634 requests in 30.05s, 43.60MB read
Requests/sec: 7076.10
Transfer/sec: 1.45MB
Running 30s test @ http://localhost/api
1 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 14.89ms 3.50ms 148.96ms 80.36%
Req/Sec 6.76k 453.18 7.79k 70.00%
201883 requests in 30.03s, 41.39MB read
Requests/sec: 6722.57
Transfer/sec: 1.38MB
Running 30s test @ http://localhost/api
1 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 15.87ms 3.65ms 73.08ms 79.70%
Req/Sec 6.34k 383.43 7.12k 73.33%
189503 requests in 30.04s, 38.86MB read
Requests/sec: 6308.24
Transfer/sec: 1.29MB
Running 30s test @ http://localhost/api
1 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 15.82ms 3.75ms 69.19ms 78.50%
Req/Sec 6.37k 365.25 7.15k 70.67%
190055 requests in 30.04s, 38.97MB read
Requests/sec: 6327.65
Transfer/sec: 1.30MB
Running 30s test @ http://localhost/api
1 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 15.65ms 3.26ms 45.16ms 76.39%
Req/Sec 6.42k 371.25 7.32k 68.33%
191781 requests in 30.02s, 39.32MB read
Requests/sec: 6388.96
Transfer/sec: 1.31MB- Aqui conseguimos ver que foi atingido uma média de 6300 requests per second
Agora esperamos que com 4 instâncias esse número aumente, né?
Running 30s test @ http://localhost/api
1 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 23.60ms 16.64ms 253.33ms 90.26%
Req/Sec 4.60k 579.94 5.53k 82.94%
136929 requests in 30.04s, 28.08MB read
Requests/sec: 4558.12
Transfer/sec: 0.93MB
Running 30s test @ http://localhost/api
1 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 21.78ms 9.24ms 136.02ms 80.28%
Req/Sec 4.70k 319.11 5.46k 68.00%
140202 requests in 30.04s, 28.75MB read
Requests/sec: 4667.48
Transfer/sec: 0.96MB
Running 30s test @ http://localhost/api
1 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 22.87ms 9.30ms 147.76ms 80.00%
Req/Sec 4.46k 348.07 5.40k 69.67%
133297 requests in 30.03s, 27.33MB read
Requests/sec: 4438.18
Transfer/sec: 0.91MB
Running 30s test @ http://localhost/api
1 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 22.80ms 9.57ms 120.30ms 79.35%
Req/Sec 4.48k 336.94 5.32k 73.33%
133747 requests in 30.06s, 27.42MB read
Requests/sec: 4449.01
Transfer/sec: 0.91MB
Running 30s test @ http://localhost/api
1 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 22.60ms 9.46ms 182.66ms 79.94%
Req/Sec 4.52k 339.69 5.67k 70.67%
134988 requests in 30.03s, 27.68MB read
Requests/sec: 4494.76
Transfer/sec: 0.92MB- O número de requests per second diminui de uma média de 6.3k para 4.4k
Isso me deixou surpreso. Eu esperava que o número de requests per second fosse aumentar independente. Pois se imagina que como esse computador tem 4 CPU Thread então 4 instâncias vai rodar paralelamente e assim processar mais requisições por segundo. Eu estava errado.
Isso se repete se aumentarmos para 400 conexões simultâneas. Isso me deixa em dúvida.
O que faz os requests per second diminuir? O fato que temos agora 4 processos concorrendo pelos os recursos da CPU? Isso tem alguma coisa haver com Context Switching?
Isso me deixou uma lição, Scaling não é óbvio. Não existe uma regra.
CASE 2: Leitura na rota /products com acesso ao banco de dados
Nessa rota é feita a leitura ao banco de dados com todos os produtos e retornado o JSON.
namespace OrderingApi.Controllers;
using Microsoft.AspNetCore.Mvc;
using OrderingApi.Data;
using OrderingApi.Domain;
using OrderingApi.View;
[ApiController]
[Route("/products")]
public class ListProductsController : ControllerBase
{
private readonly ILogger<ListProductsController> _logger;
private readonly ApplicationContext _context;
public ListProductsController(
ILogger<ListProductsController> logger,
ApplicationContext context
)
{
_logger = logger;
_context = context;
}
[HttpGet]
public ActionResult<HttpResponse> List()
{
var products = _context.Products
.ToList<Product>()
.Select(p =>
{
var view = new ProductView();
view.setValues(p);
return view;
})
.ToList();
return Ok(products);
}
}Agora iremos testar a rota com 400 conexões simultâneas com o seguinte comando:
seq 1 5 | xargs -n1 wrk -t1 -c400 -d30s http://localhost/products >> benchmarks/products-1-replica-400-conn-1-th.logResultado:
Running 30s test @ http://localhost/products
1 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 214.14ms 40.40ms 377.66ms 69.97%
Req/Sec 1.87k 693.63 3.58k 69.02%
55729 requests in 30.01s, 78.55MB read
Requests/sec: 1857.23
Transfer/sec: 2.62MB
Running 30s test @ http://localhost/products
1 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 217.81ms 40.14ms 386.65ms 72.29%
Req/Sec 1.86k 725.85 4.00k 69.31%
54971 requests in 30.10s, 77.48MB read
Requests/sec: 1826.43
Transfer/sec: 2.57MB
Running 30s test @ http://localhost/products
1 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 232.70ms 46.28ms 403.38ms 72.31%
Req/Sec 1.75k 789.05 4.17k 68.21%
51379 requests in 30.08s, 72.42MB read
Requests/sec: 1707.86
Transfer/sec: 2.41MB
Running 30s test @ http://localhost/products
1 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 230.06ms 52.18ms 520.58ms 73.17%
Req/Sec 1.77k 756.21 4.02k 67.26%
51968 requests in 30.09s, 73.25MB read
Requests/sec: 1727.20
Transfer/sec: 2.43MB
Running 30s test @ http://localhost/products
1 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 222.65ms 42.33ms 439.29ms 70.99%
Req/Sec 1.80k 765.37 4.16k 68.03%
53761 requests in 30.08s, 75.78MB read
Requests/sec: 1787.31
Transfer/sec: 2.52MB- O resultado foi uma média de 1.7/1.8k requests per second.
Agora com 4 replicas/instâncias da API REST e 400 conexões simultâneas, temos:
Running 30s test @ http://localhost/products
1 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 385.02ms 364.10ms 1.96s 74.91%
Req/Sec 0.96k 477.99 2.66k 69.72%
10631 requests in 13.58s, 14.98MB read
Socket errors: connect 0, read 0, write 0, timeout 400
Requests/sec: 782.88
Transfer/sec: 1.10MB
Running 30s test @ http://localhost/products
1 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 327.58ms 256.31ms 1.74s 70.83%
Req/Sec 1.32k 418.38 2.68k 67.00%
39571 requests in 30.11s, 55.78MB read
Socket errors: connect 0, read 0, write 0, timeout 34
Requests/sec: 1314.10
Transfer/sec: 1.85MB
Running 30s test @ http://localhost/products
1 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 338.75ms 278.96ms 1.89s 73.22%
Req/Sec 1.33k 453.85 2.93k 69.33%
39789 requests in 30.07s, 56.08MB read
Socket errors: connect 0, read 0, write 0, timeout 2
Requests/sec: 1323.14
Transfer/sec: 1.87MB
Running 30s test @ http://localhost/products
1 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 337.75ms 279.77ms 1.74s 71.32%
Req/Sec 1.33k 439.08 2.74k 71.24%
39580 requests in 30.07s, 55.79MB read
Socket errors: connect 0, read 0, write 0, timeout 29
Requests/sec: 1316.05
Transfer/sec: 1.86MB
Running 30s test @ http://localhost/products
1 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 323.04ms 249.77ms 1.90s 72.06%
Req/Sec 1.36k 431.41 2.88k 71.57%
40480 requests in 30.07s, 57.06MB read
Socket errors: connect 0, read 0, write 0, timeout 5
Requests/sec: 1346.30
Transfer/sec: 1.90MB
Running 30s test @ http://localhost/products
1 threads and 400 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 365.25ms 334.49ms 2.00s 77.03%
Req/Sec 1.31k 458.01 2.96k 72.88%
38535 requests in 30.09s, 54.32MB read
Socket errors: connect 0, read 0, write 0, timeout 52
Requests/sec: 1280.74
Transfer/sec: 1.81MB- Uma queda de 1.7k para 1.3k requests per second.
- Em alguns momentos ocorreu Socket errors do tipo timeout. Provável que os requests foram descartados pelo a demora de ser processado.
E então porque o aumento de instâncias está fazendo a API REST aceitar menos requisições? Não foi óbvio de primeira, mas depois de um tempo descobri.
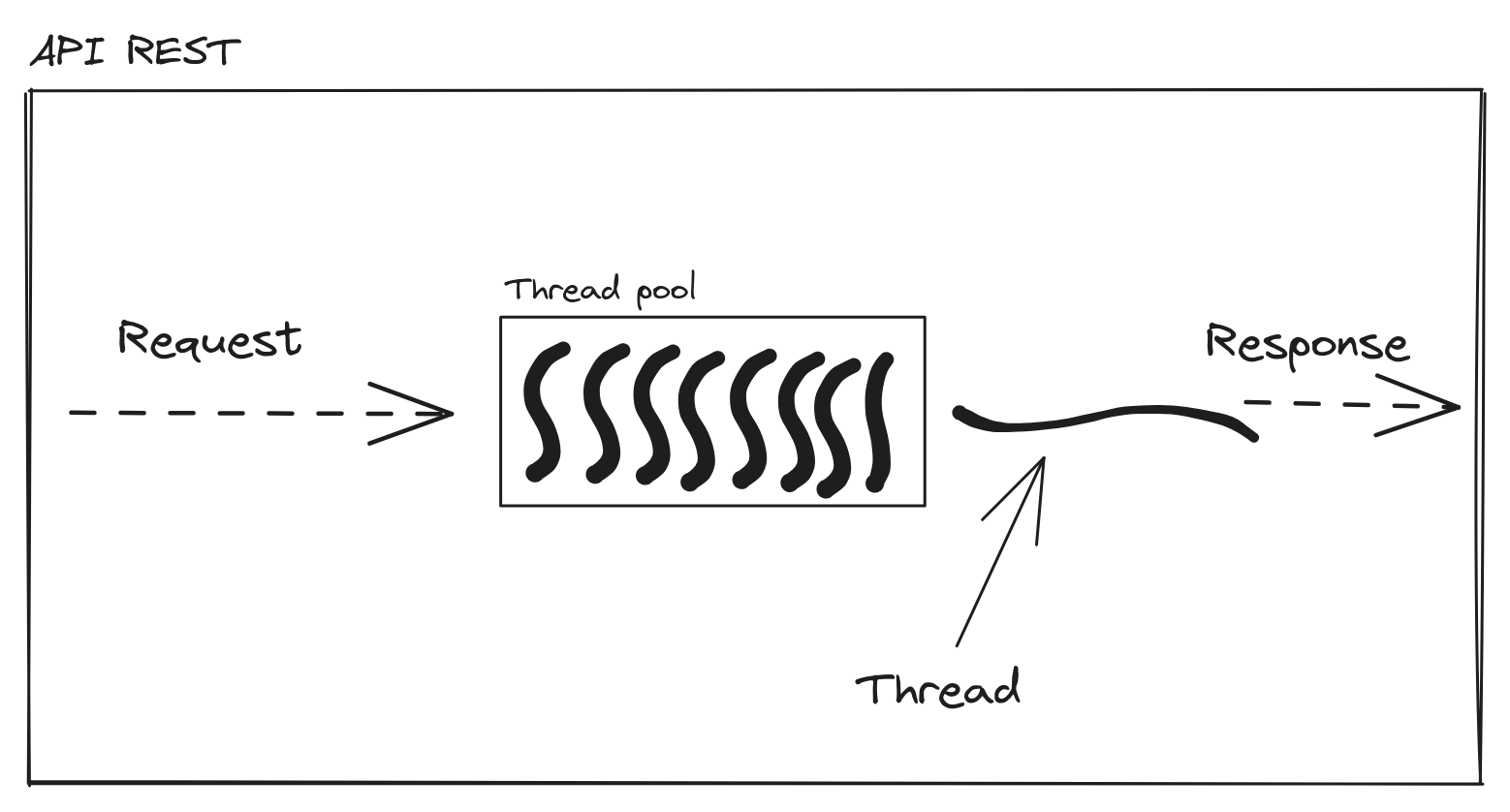
Thread Pool
ASP.NET MVC não precisa de replicas para processar as requisições paralelamente na mesma máquina. DotNet fornece uma ThreadPool, que é basicamente o que estou tentando fazer aqui, onde nós temos N recursos para processar uns dados. O recurso que estamos usando aqui é instâncias da API REST com Docker container, no DotNet é uma thread. Em que cada thread executa o código de uma request.
Quando estava tentando rodar 4 instâncias tudo que eu fazia era adicionar mais concorrentes para os recursos da máquina, já que cada instância tem threads o suficiente para executar paralelamente a nível de CPU Thread. Isso fazia com que tivesse menos recursos ainda disponíveis para a API REST e trazendo mais custos como Context Switching entre as instâncias.
Um dos Docker containers rodava e assim consumia todas as 4 CPU Thread disponíveis no meu computador. Então uma única instância utilizando bem os recursos da CPU. Colocar mais 3 instâncias só faz aumentar a concorrência entre os 4 processos da API REST rodando.
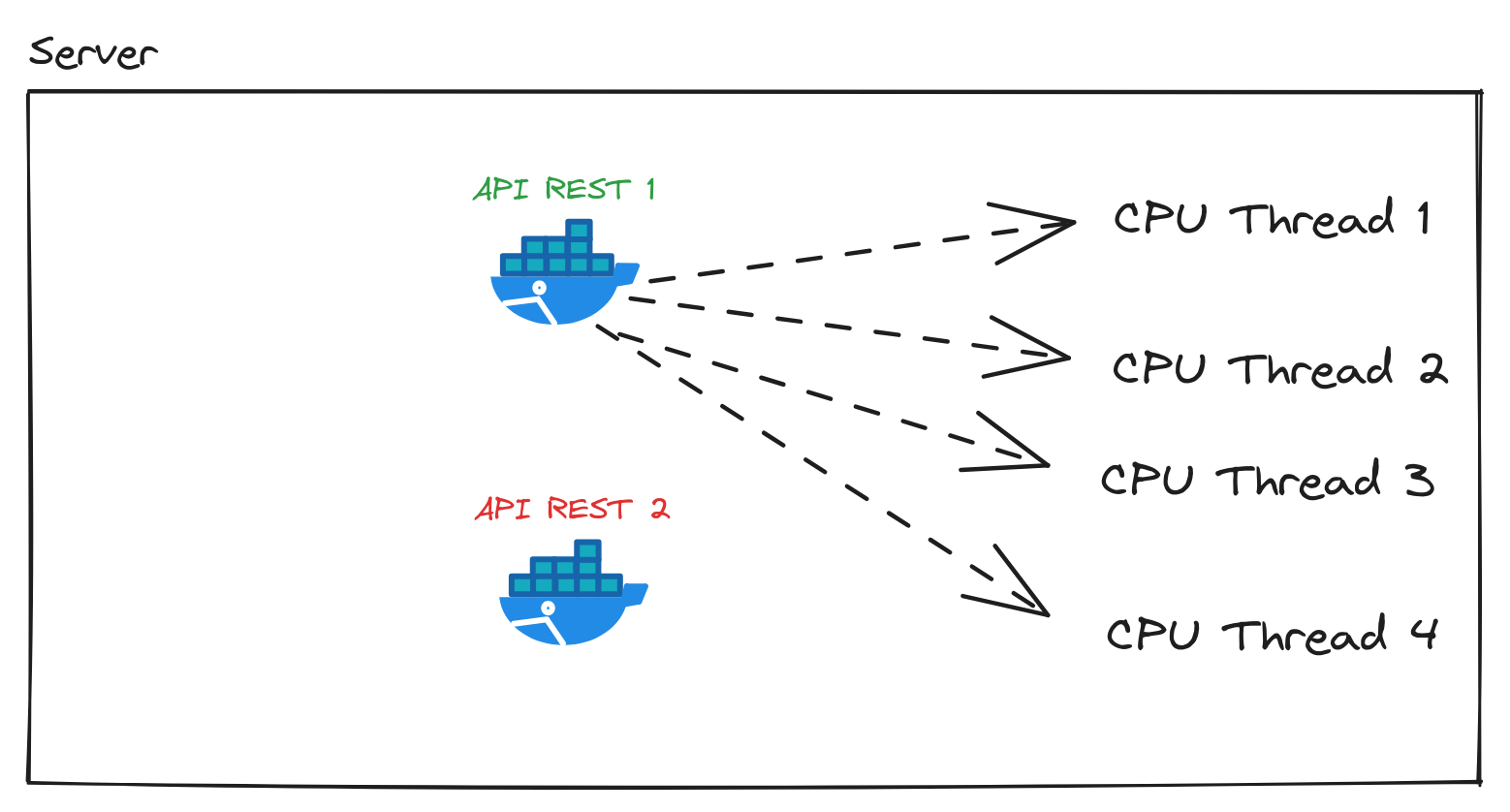
Em algum momento o Scheduler da Kernel resolveu dar vez para a API REST 2. Essa troca de contexto e execução entre processos e threads, é Context Switching.
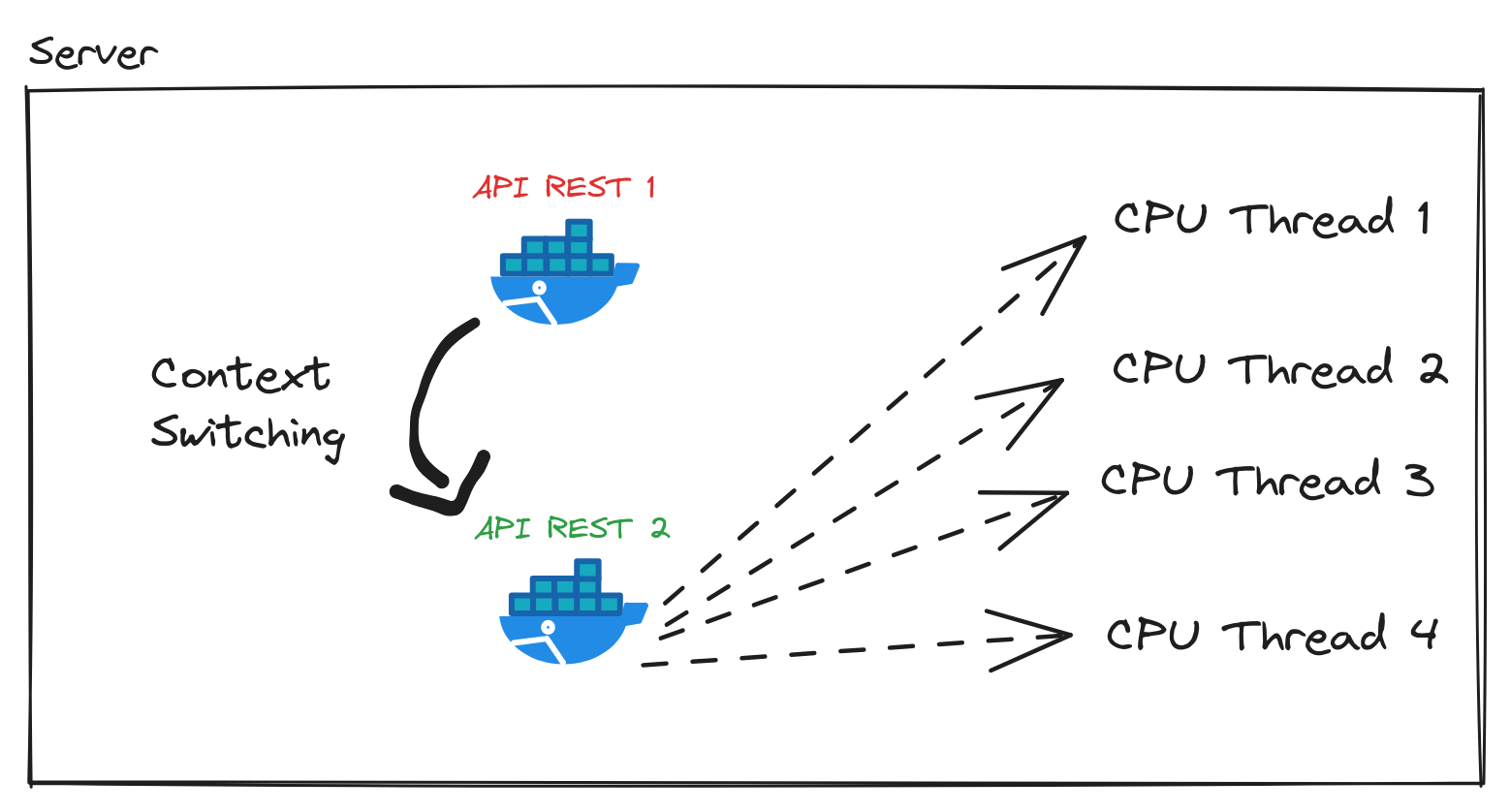
Context Switching não é de graça e nem barato, porque tem um custo a mais para a CPU. Como pode ser visto nos resultados do load test os requests per second diminui em uma quantidade considerável. Por isso com 4 instâncias ficou mais lento, graças a essa troca (switching) de contexto (context) feita e que trouxe benefício nenhum para esse caso, só mais custo.
Para investigar isso utilizei o comando htop após iniciar o load testing com wrk. E vi que com uma instância da API REST rodando as 4 threads disponíveis da máquina estavam sendo utilizadas.

Meu erro foi não considerar a arquitetura da linguagem de programação e do framework. Se isso fosse Node.JS ou Python estaria tudo bem, porque Node.JS ou Python é single thread. Mas DotNet/C# é multithread.
Isso quer dizer que a API REST em C# não pode escalar? Não. Eu tentei fazer utilizando cada thread do meu computador como se fosse um virtual server na AWS ou Google Cloud. Como se cada instância estivesse no seu próprio virtual server. Mas a arquitetura do ASP.NET MVC e C# não permite isso.
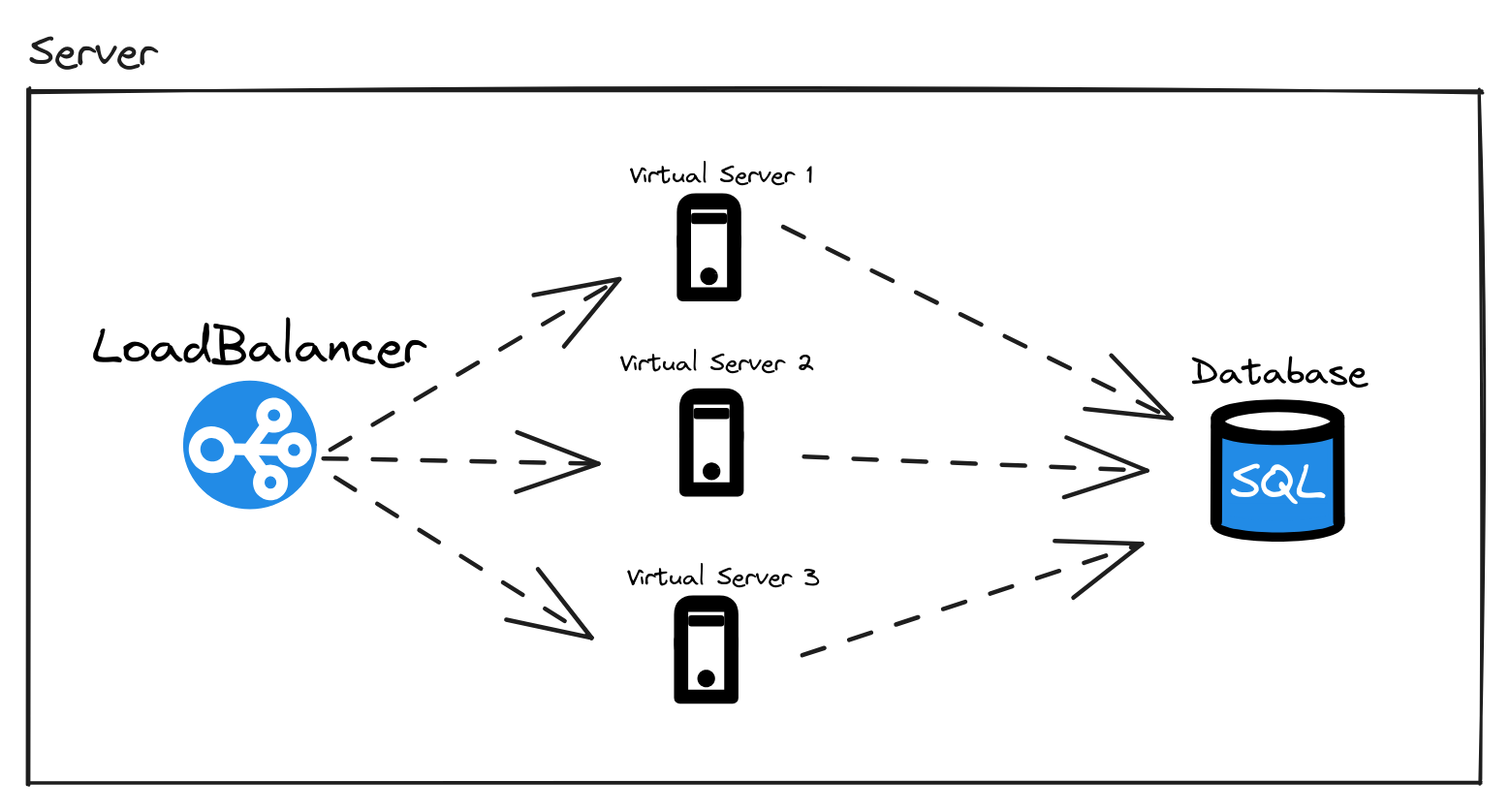
É possível escalar uma aplicação multithread como essa. Utilize cada instância da API REST multithread em um virtual server, assim como o Nginx e o banco de dados, e comunicação entre o Nginx e as instâncias seria feito via rede utilizando a URL dos virtual servers na upstream assim como foi feito com o nome do serviço Docker.
Conclusão
Esperava um resultado e ver sobre um assunto específico, mas acabei indo para Thread Pool, Context Switching e Framework Architecture. Isso mostra o quão enganados estamos no começo de uma jornada, mas também traz ensinamentos após ela.
Aprendi muito com essa prática e me mostrou alguns conhecimentos que pensei que não tinha haver com isso mas no final acabou tendo.
- Aprendi como um load balancer funciona
- Como utilizar load testing para entender mais sobre concorrência e paralelismo com API REST
- Como Thread Pool funciona
- Como Thread Pool e Load balancer tem conceitos fundamentais muito parecidos
- Como investigar problemas de concorrência
O código dessa aplicação está no seguinte repositório, espere por novos assuntos e posts. Fiquem bem.